

کلان-داده-یا-بیگ-دیتا- چیست؟
کلان-داده-یا-بیگ-دیتا- (Big Data) به نقش ها و شیوه های مورد نیاز برای جمع آوری، مدیریت، قاعده مند سازی و ارائه مجموعه ای از کلان-داده-یا-بیگ-دیتا- Big Data اشاره دارد که به شرکت ها در تصمیم گیری آگاهانه تر و مبتنی بر واقعیت کمک می کند. کلان-داده-یا-بیگ-دیتا-در کل شرکت بسیار مهم شده اند. بر تصمیمات کسبو کار تأثیر می گذارد، به ایجاد محصولات بهتر کمک می کند، توسعه محصول را بهبود می بخشد و کارایی عملیاتی را افزایش می دهد. این مقاله نقش حیاتی داده ها در سازمان، فرآیند DataOps برای مدیریت و ارائه حجم گسترده داده و نحوه اعمال DataOps را شرح می دهد.
در عصر دیجیتال، شرکت ها داده ها را با سرعت شگفت انگیزی تولید می کنند. هر کلیک وب سایت، چرخش موتور توربین، سرعت در انتقال اطلاعات و تراکنش کارت اعتباری اطلاعات جدیدی در مورد محصولات، مصرف کنندگان و محیط های عملیاتی ایجاد می کند. شتاب سریع اطلاعات منجر به شیوه های جدیدی برای ذخیره سازی، مدیریت و ارائه مجموعه های عظیم داده شده است. همانطور که شکل ۱ نشان می دهد، این شیوه هایکلان-داده-یا-بیگ-دیتا- ، محصولاتی را که براساس داده ایجاد شده اند را برای ارائه ارزش در کل شرکت ارائه می دهد.
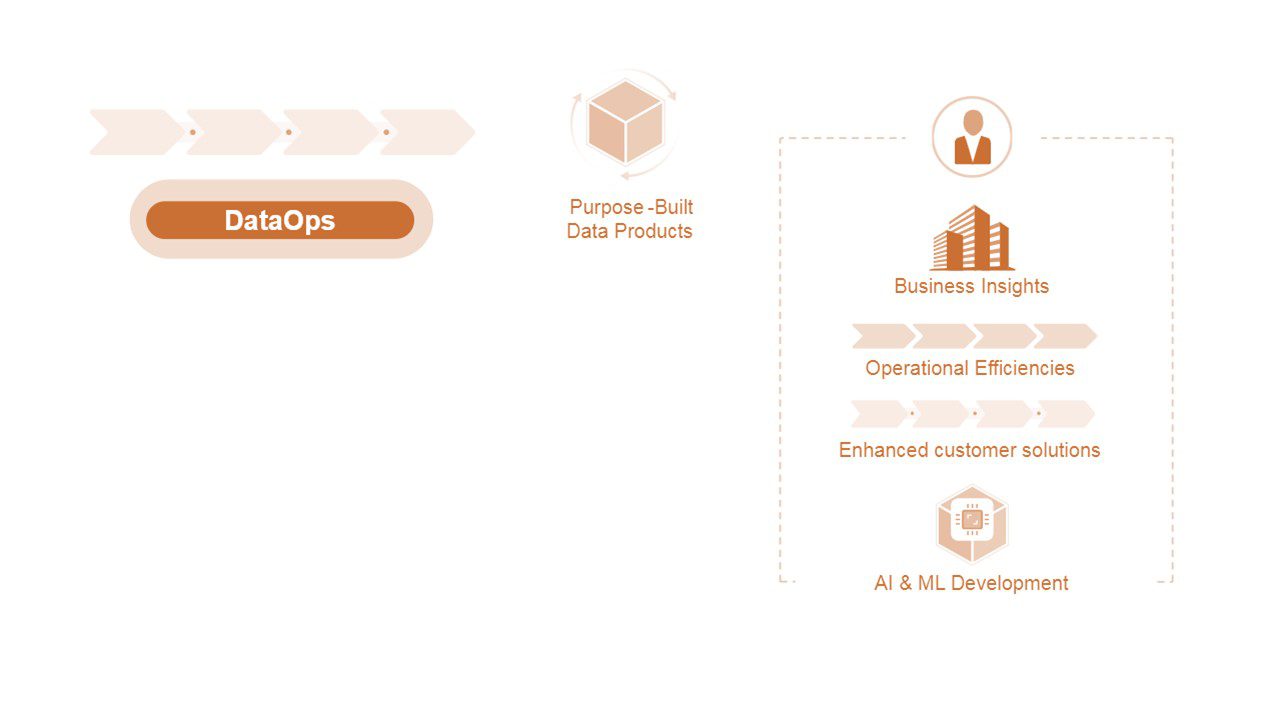
شکل ۱. محصولات Big Data از تمام بخش های سازمان پشتیبانی می کنند
نقش در حال تحول کلان داده ها در سازمان
انباشت داده ها معمولاً در سیلوهای سازمانی آغاز می شود. یک بخش اطلاعات مربوط به کاربران و سیستم ها برای بهبود محصولات، کشف پیشرفت های عملیاتی، بهبود بازاریابی و فروش و غیره جمع آوری می کند. در حالی که این دادههای متمایز ارزشمند هستند، جمعآوری مجموعههای کلان-داده-یا-بیگ-دیتا- در کل سازمان ارزش بیشتری را نسبت به این داده ها فراهم میکند.
بهره برداری از داده های بزرگ برای مزیت رقابتی
هر سازمانی از کلان-داده-یا-بیگ-دیتا- (Big Data) برای بهبود محصولات خود، بهینه سازی عملیات و درک بهتر مشتریان و بازارهای خود استفاده می کند. رسانهها و سازمانهای محصولات مصرفکننده از راهحلهای کلان داده برای ایجاد مدلهای پیشبینی برای محصولات و خدمات جدید برای پیشبینی تقاضای مشتری استفاده میکنند. تولید از راه حل های کلان-داده-یا-بیگ-دیتا-(Big DATA) برای تعمیر و نگهداری برای پیش بینی خطاها استفاده می کند. کسبوکارهای خردهفروشی از راهحلهای کلان-داده-یا-بیگ-دیتا- (Big Data)داده برای بهبود تجربیات مشتری و مدیریت موثر زنجیرههای تامین استفاده میکنند. سازمان های مالی از راه حل های کلان-داده-یا-بیگ-دیتا- برای جستجوی الگوهایی در داده ها استفاده می کنند که نشان دهنده تقلب بالقوه است.
حمایت از ابتکارات هوش مصنوعی
سازمان ها از هوش مصنوعی (AI) و یادگیری ماشینی (ML) به عنوان یک مزیت رقابتی برای ارائه محصولات بهتر به مشتریان خود، بهبود کارایی عملیاتی و توسعه، و ارائه بینشی که کسب و کار را بهبود می بخشد، استفاده می کنند. ابتکارات هوش مصنوعی متمرکز بر یادگیری ماشینی به مجموعههای بزرگی از دادههای غنی برای آموزش و اعتبارسنجی مدلها نیاز دارد.فقدان داده های کافی یک دلیل رایج برای شکست ابتکارات هوش مصنوعی است. برای دستیابی به اهداف هوش مصنوعی، یک سازمان باید رویکردی در سطح سازمانی برای جمعآوری، مدیریت و ارائه دادههای جمعآوریشده در سراسر سازمان به همراه دادههای خارجی برای پر کردن شکافها ایجاد کند.
چالش های کلان داده
جمع آوری این داده ها چالش هایی را ایجاد می کند. ویژگیهای جامعه کلان-داده-یا-بیگ-دیتا-را با “۳ Vs”: مشخص میکنند:
حجم – کسب معرفت از داده ها به طیف گسترده ای از داده های جمع آوری شده در سراسر سازمان نیاز دارد که می تواند به صدها پتابایت برسد. به عنوان مثال، گوگل هر روز ۲۰ پتابایت داده وب را پردازش می کند. راه حل های کلان داده باید حجم عظیمی از داده ها را جمع آوری، تجمیع و به مصرف کنندگان داده تحویل دهند.
سرعت – تصمیمات مبتنی بر داده نیازمند آخرین داده ها هستند. سرعت تعیین می کند که داده های جدید با چه سرعتی از منابع داده دریافت و به روز شوند. به عنوان مثال، موتور بوئینگ ۷۳۷ هر ساعت ۲۰ ترابایت اطلاعات تولید می کند. راه حل های کلان-داده-یا-بیگ-دیتا- باید تصمیم بگیرند که کدام داده و برای چه مدت ذخیره شوند.
تنوع – داده ها به اشکال مختلف در سراسر سازمان استخراج می شوند. ذخیره و تجزیه و تحلیل داده های سنتی از پایگاه های داده، صفحات گسترده و متن آسان است. دادههای بدون ساختار شامل ویدئو، تصاویر و حسگرها چالشهای جدیدی را ارائه میکنند.
اخیراً، جامعه داده تنوع، صحت، ارزش، دید و سایر موارد را اضافه کرده است تا داده های بزرگ را بیشتر مشخص کند و به چالش های ذخیره، مدیریت و ارائه آن بیافزاید.
DataOps را در Enterprise بشناسیم
برای مقابله با چالش هایکلان-داده-یا-بیگ-دیتا- سازمان ها نیاز به یک رویکرد واحد دارند. جامعه علوم داده مراحل سازمان ها را در سلسله مراتب نیازهای علم داده می شناساند. این داده ها و ذخیره سازی آن برای ایجاد برنامه ای برای استفاده گسترده تر بهینه شده است. همانطور که این داده ها به سازمان مربوط می شوند، مهندسان داده (معمولاً به عنوان بخشی از یک تابع داده متمرکز) مجموعه های گسترده تری از داده های برنامه را به یک مخزن داده تبدیل و در آن ذخیره می کنند تا از طریق محصولات داده مانند marts، cubsو view ها در دسترس قرار گیرند. تحلیلگران داده و سایرین از محصولات فقط خواندنی و مناسب برای تجزیه و تحلیل آماری و تجسم استفاده میکنند. دانشمندان داده از آنها برای توسعه و آموزش مدل هایی برای هوش مصنوعی و ML استفاده می کنند. افراد اغلب نقش های متعددی را ایفا می کنند. به عنوان مثال، یک تحلیلگر داده که داشبوردی را با مهارت های مهندسی داده ایجاد می کند، ممکن است برای تبدیل و جمع آوری مجدد داده ها برای یک نمای جدید یا به روز شده، به انبار داده برگردد. با این حال، قوانین حاکمیت یک سازمان ممکن است توانایی افراد را برای فعالیت در بخشهای مختلف هرم محدود کند. در حالی که بیشتر سازمان ها یک رویکرد انبار داده متمرکز به داده ها دارند، استراتژی های توزیع شده مانند Data Mesh به ویژه برای سازمان های بزرگ در حال ظهور هستند.
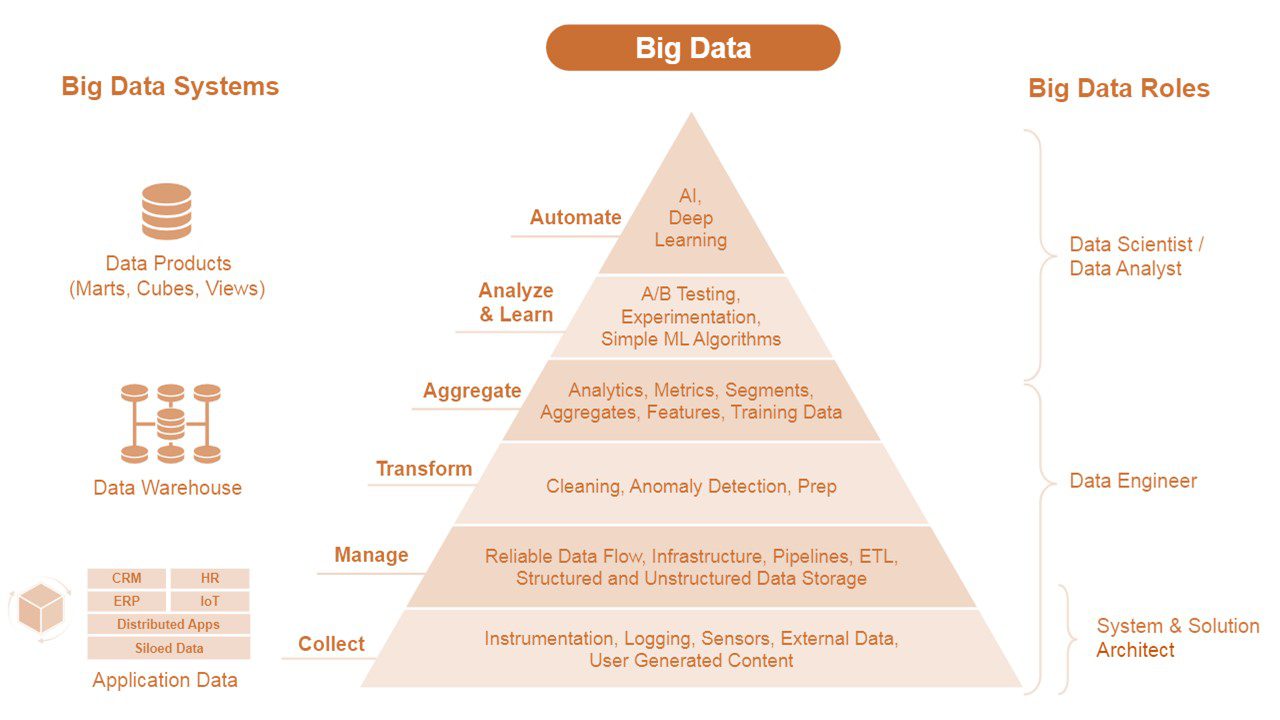
شکل ۲. سلسله مراتب نیازهای علم داده
چرخه حیات DataOps
اقداماتکلان-داده-یا-بیگ-دیتا- در بالا به عنوان بخشی از مدل چرخه حیات DataOps که در شکل ۳ نشان داده شده است به طور مداوم انجام می شود. DataOps یک فعالیت مدیریت داده مشترک در میان تیمهای Agile، متخصصان داده و ذینفعان سازمانی است که از طرز فکر، اصول و شیوههای Lean-Agile و DevOps برای ارائه محصولات داده با کیفیت قابل پیشبینی و قابل اعتماد استفاده میکند. بخش بالای چرخه عمر نشان میدهد که چگونه دادههای خاص برنامه ها در محصولات دادهای که به مصرفکنندگان مختلف ارائه میشود، جریان دارد. بخش پایین نشان میدهد که چگونه دادهها مصرف میشوند، کنترل میشوند و برای بهبود راهحلهایی استفاده میشوند که حتی دادههای بیشتری را در خط لوله تولید میکنند. بقیه این بخش هر فعالیت DataOps را شرح می دهد.
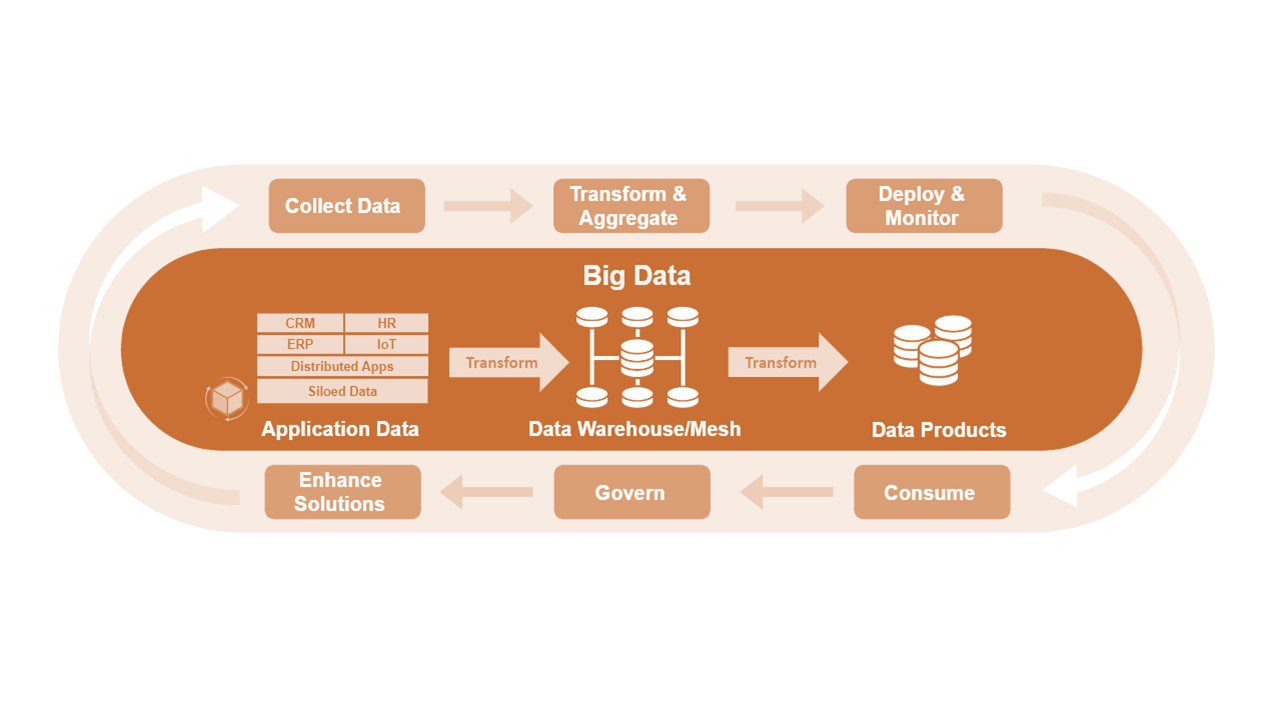
شکل ۳. چرخه حیات DataOps
جمع آوری داده ها – معماران سیستم و راه حل، تیم های چابک ومدیران سیستم دور سنج می سازند، وارد سیستم می شوند و در مورد سیستم و رفتارهای کاربر برای جمع آوری داده ها اقدام به نظارت می کنند. معماران سیستم اطمینان میدهند که راهحلها به راحتی کاربردی هستند و درست طراحی شده اند ، بنابراین میتوان به دادههای برنامه به صورت خارجی، اغلب از طریق APIها، دسترسی داشت. همانطور که دادهها برای شرکتهای بزرگتر حیاتیتر میشوند، کار برای جمعآوری دادههای بهتر و افشای آنها از طریق APIها ممکن است در اولویت قرار گیرد و به تخصیص ظرفیت نیاز داشته باشد (به ART Backlog مراجعه کنید) تا از تعادل مناسب با سایر backlogs اطمینان حاصل شود.
جمع آوری و تبدیل – مهندسان داده، دادهها را از سراسر سازمان به شکلهای قاعده مند، تبدیل و جمع آوری میکنند که برای استفاده کارآمد توسط مصرفکنندگان داده بهینهسازی شدهاند. یک معماری داده متمرکز، ذخیره سازی کارآمد و تحویل محصولات داده های ثابت را در سراسر سازمان تضمین می کند. مهندسان داده باید «درVS»هایی را که قبلاً بحث شد متعادل کنند و تعیین کنند که کدام داده ذخیره شود، چه مدت، زمان دسترسی قابل تحمل و غیره. آنها داده ها را به عنوان یک محصول می بینند و تفکر طراحی و کیفیت داخلی را اعمال می کنند. Personas و Journey Maps به آنها کمک میکند تا با دردها، دستاوردها و تجربیات کاربران دادهها همدلی کنند و نحوه ارائه محصولات داده بهتر را تعیین کنند.
Monitor – مهندسان داده، محصولات داده را از انبار داده به اشکال مختلف، از جمله دادهها، کیوب ها و از منظرنحوه استفاده مصرفکنندگان داده ، مستقر میکنند. مانند دیگر راهحلهای فناوری ، راهحلهای داده از فناوری Cloud بهره میبرند و تحویل مداوم را از طریق خط لوله DevOps که برای دادهها طراحی شده است، اعمال میکنند. این شیوهها به سرعت تغییرات دادهها را از طریق توسعه، Q/A، UAT و محیطهای تولید برای بازخورد مصرفکننده منتقل میکنند. محیطهای متعدد تضمین میکنند که داشبوردها، گزارشها، مدلها و سایر مصنوعات وابسته به محتوای دادهها و قالبها میتوانند با دادهها تکامل یابند. در DevOps، نظارت در تمام مراحل خط لوله داده برای شناسایی ناهنجاریها در دادهها (شمارش ردیف، دادههای خارج از محدوده) و عملیات داده (وقفههای زمانی غیرمنتظره) انجام میشود و هشدارهایی را به تیم داده ارسال میکند.
مصرف – مصرف کنندگانکلان-داده-یا-بیگ-دیتا- را می توان به دو گروه طبقه بندی کرد، همانطور که در شکل ۴ نشان داده شده است. تحلیلگران از محصولات داده برای کشف بینش و تجسم مشتریان داده خاص استفاده می کنند. دانشمندان داده و توسعه دهندگان ML از آنها برای توسعه و آموزش مدل ها استفاده می کنند. مشتریان آنها (مشتریان داده در شکل ۴) ذینفعانی در سطح شرکت هستند که به دنبال بینش تجاری برای تصمیم گیری، بهبود عملیات و بهبود راه حل ها هستند. خطوط مختلف کسب و کار، مدیران محصول، توسعه دهندگان هوش مصنوعی و سایرین نیازهای داده منحصر به فردی دارند. برای فعال کردن این افراد از طریق یک مدل خود خدمت، شرکتها باید روی ابزارها، بستههای تحلیلی و منابعی سرمایهگذاری کنند تا از دسترسی موقت برای دستکاری محلی پشتیبانی کنند. این سرمایه گذاری بار اعضای تیم داده متمرکز را برای گزارش دهی و سایر کارهای روزمره کاهش می دهد.
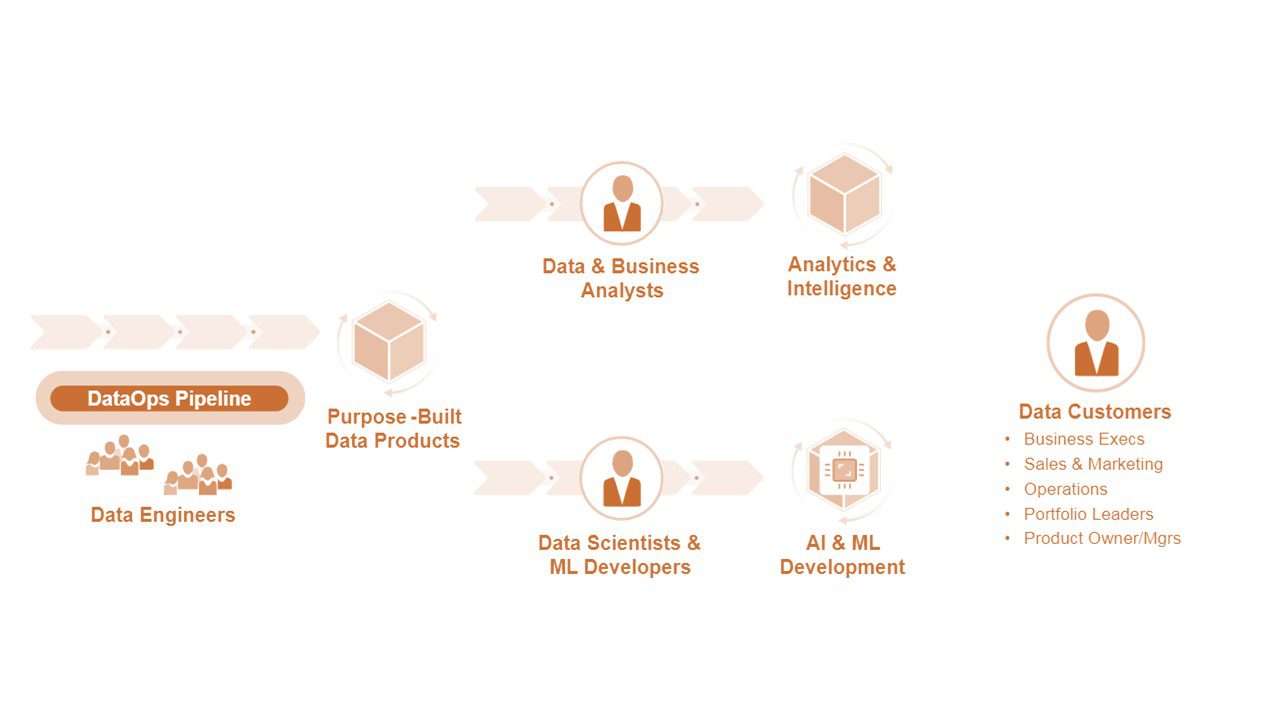
شکل ۴. کلان-داده-یا-بیگ-دیتا- مشتریان زیادی در کل شرکت دارد.
DataOps باید حریم خصوصی داده ها، محرمانه بودن، اقامت، اشتراک گذاری، حفظ و سایر الزامات قانونی را اعمال کند. راه حل کلان-داده-یا-بیگ-دیتا- باید از طریق کنترل های دسترسی، ممیزی و نظارتی که نفوذ و نقض داده ها را شناسایی می کند، امنیت را تضمین کند. مانند سایر محصولات دیجیتال، باید تحمل خطا و بازیابی فاجعه را از طریق فروشندگان یا راه حل های خانگی ارائه دهد.
راه حل ها را افزایش دهید – رهبران نمونه کارها و قطار انتشار چابک (ART) از داده ها برای بهبود راه حل هایی استفاده می کنند که ارزش مشتری (محصولات بهتر) و ارزش تجاری (داده های بهتر) را ارائه می دهند. تجزیه و تحلیل داده ها می تواند فرصت هایی را برای ارائه راه حل های جدید نشان دهد و اولویت بندی ویژگی ها را برای راه حل های موجود اطلاع دهد. شکاف های داده همچنین فرصت هایی را برای بهبود راه حل ها برای جمع آوری داده های اضافی نشان می دهد.
استفاده از DataOps
بخش های قبلی اهمیت یک استراتژی داده واضح و قانع کننده را شرح می دهد. این بخش راهنماییهای بیشتری را که سازمانها میتوانند برای حمایت از سفر دادههای بزرگ خود اتخاذ کنند، توضیح میدهد.
DataOps یک مساله مهم برای پورتفولیو است
پرداختن به مسائل مرتبط با کلان داده در سطح پورتفولیو به بررسی چشم انداز، سرمایه گذاری و حاکمیت سازمانی در بالاترین سطوح سازمان کمک می کند(شکل ۵). در حالی که ART ها داده ها را ایجاد می کنند، ارزش از تجمیع داده ها در سطوح پورتفولیو و شرکت می آید. راهحلهای کلان-داده-یا-بیگ-دیتا- مستلزم سرمایهگذاری استراتژیک از سوی سازمان و رویکردی جامع است که هر یک از جریانهای ارزش توسعه سازمان را با شیوههای رایج DataOps که مجموعه دادههای منسجمی را تولید میکند و در کل سازمان استفاده میشود، همسو میکند. رهبران پورتفولیو از بودجه ناب برای سرمایه گذاری در زیرساخت داده های بزرگ و شیوه های DataOps برای انجام این کار استفاده می کنند. آنها همچنین از Portfolio Epics و Portfolio Backlog برای تعیین و اولویت بندی زیرساخت ها، فناوری ها و داده های مورد نیاز برای پشتیبانی از سازمان استفاده می کنند (شکل ۵).
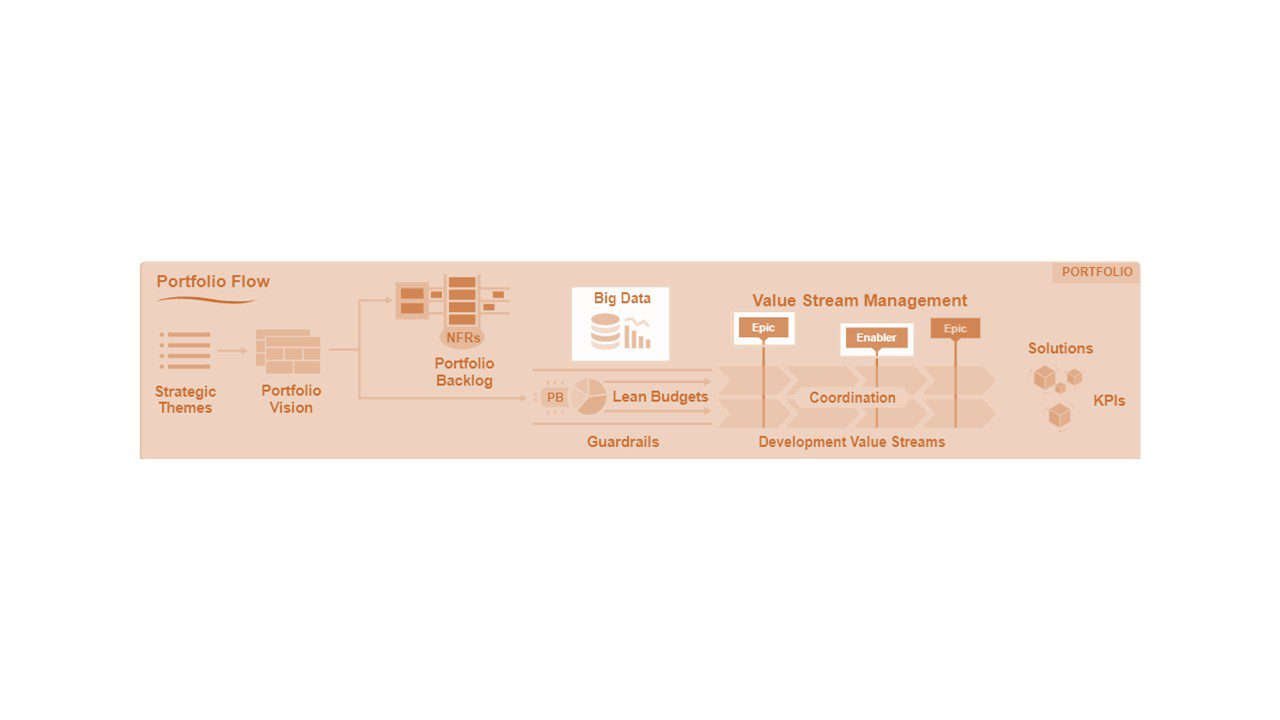
شکل ۵. کلان داده مشتریان زیادی در کل شرکت دارد
در ابتدا بر عملکرد داده متمرکز شوید
سازماندهی حول ارزش، تلاش می کند تا جریان را با حصول اطمینان از اینکه تیم ها و ART ها تمام مهارت های لازم برای ارائه ارزش را دارند، بهینه کند. متأسفانه، بیشتر سازمانها هنوز در حال رشد عملکردهای مهندسی داده و علوم خود هستند و در نتیجه تقاضای بیشتری نسبت به ظرفیت برای این مهارتها دارند.تمرکز اولیه اغلب برای پذیرش فناوری اولیه برای به حداکثر رساندن مهارت های موجود و ایجاد زیرساخت ها و شیوه های DataOps مفید است. تمرکز نیز مدیریت حریم خصوصی و امنیت را ساده میکند که حفاظت از آنها با رویکرد سلبشده عملاً غیرممکن است. این تابع متمرکز میتواند بیشتر نیازهای دادهای سازمان را از طریق رویکردهای مشتری محوری که قبلاً توضیح داده شد، برآورده کند. همانطور که در شکل ۶ نشان داده شده است، در مواردی که پشتیبانی اضافی مورد نیاز است، الگوی شناخته شده ای از ارائه خدمات اضافی به سایر بخش های سازمان از طریق یک سرویس مشترک وجود دارد. با گذشت زمان، سازمان ها عملکردهای داده خود را برای حمایت از شرکت های گسترده تر و جاسازی افراد در ARTs و جریان های ارزش عملیاتی توسعه خواهند داد. با این حال، یک جریان ارزش توسعه کلان-داده-یا-بیگ-دیتا- از مهندسان داده که داده های سازمانی انبوه را ارائه می دهند احتمالاً برای مدتی وجود خواهد داشت.
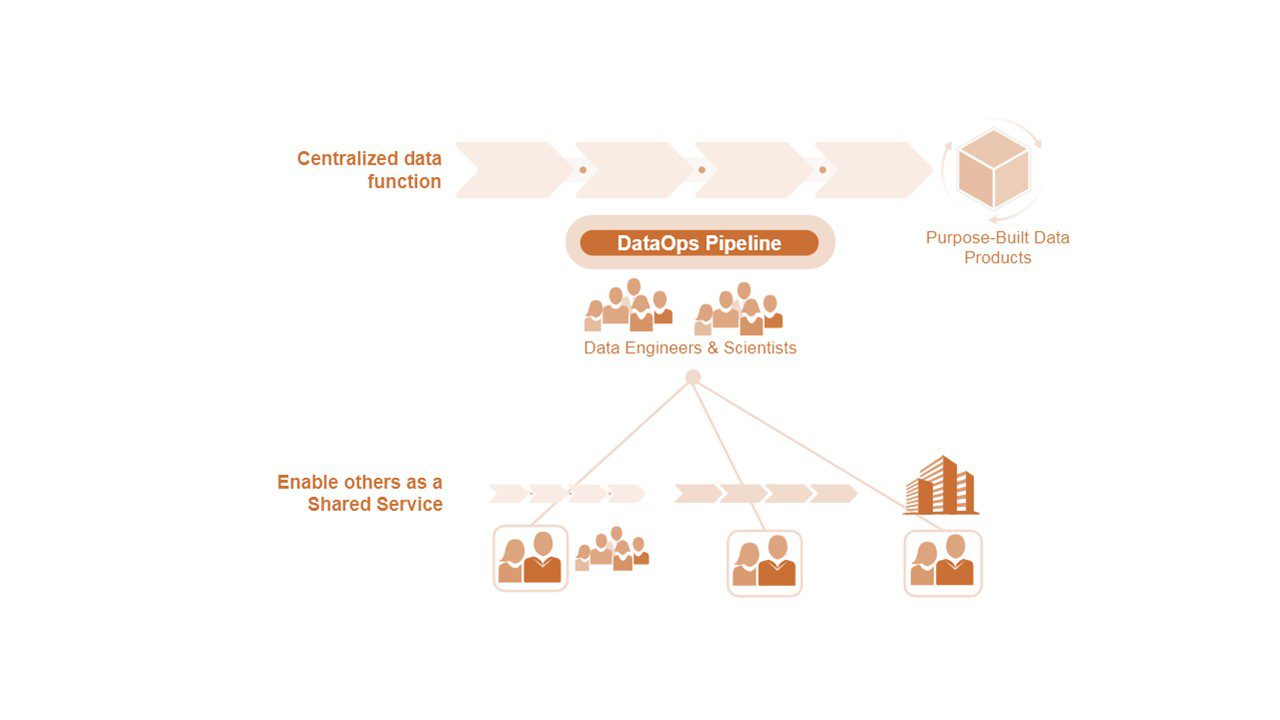
شکل۶.با متمرکز ساز عملکرد داده شروع کنید که از سایر بخش های سازمان به عنوان یک سرویس مشترک پشتیبانی می کند.
رشد استعدادهای فنی
مهندسی داده، تحلیل و مهارتهای توسعهدهنده AI/ML در حجم بالای تقاضا و به کارگیری دادههای تخصصی و مهارتی یک چالش مهم است. سازمان ها برای جذب و حفظ این استعدادها باید داده ها و چشم انداز هوش مصنوعی قانع کننده و الهام بخش ایجاد کنند. متخصصان داده میخواهند از دیگر متخصصان داده یاد بگیرند و رشد کنند تا با فناوریها و شیوههای بهسرعت در حال تحول همگام شوند.
استفاده از DataOps برای ساخت راه حل های بهتر
راهحلها باکلان-داده-یا-بیگ-دیتا- اطلاعرسانی و تقویت میشوند، و تیم ای آر تی به مهارتهای علم داده و مهندسی داده نیاز دارند. همانطور که قبلا توضیح داده شد، کارکردهای داده می تواند منابعی را به عنوان یک سرویس اشتراکی در اختیار ART ها قرار دهند. اما آنها باید کار ART را با مسئولیت اصلی خود برای ایجاد و تکامل شیوههای DataOps که شامل ارائه محصولات داده به شرکت است، متعادل کنند. هنگام حمایت از ART ها، آنها باید مانند یک تیم توانمند (به تیم های چابک مراجعه کنید) عمل کنند تا شایستگی داده های فنی را در سراسر سازمان رشد دهند. در این مقام، آنها برای انجام کار نیستند، بلکه برای آموزش نحوه انجام آن به دیگران هستند.
جهت ارتقاء سطح کیفی مقالات و تکمیل مباحث مربوطه، لطفا نظرات و دیدگاههای خود را در پایان این مقاله درج کنید، همچنین چند مقاله مرتبط با موضوع چشم انداز پورتفولیو برای مخاطبان سایت شریف استراتژی به اشتراک گذاشته شده است.







در گفتگو ها شرکت کنید.